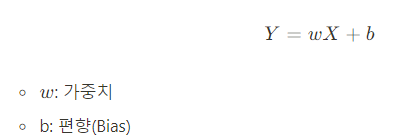기술 통계 등을 통하여 집계된 정보로 의사결정을 했던 과거와 달리 데이터 수집과 처리 기술의 발전으로 대용량 데이터의 패턴을 인식하고 이를 바탕으로 예측, 분류하는 방법론
머신러닝 종류
지도학습 : 문제와 정답을 모두 알려주고 공부시키는 방법 비지도 학습 : 답을 가르쳐주지 않고 공부시키는 방법 강화 학습 : 보상을 통해, 상을 최대화, 벌을 최소화하는 방향으로 행위를 강화하는 학습
선형회귀
알려진 다른 관련 데이터 값을 사용하여 알 수 없는 데이터의 값을 예측하는 데이터 분석 기법 통계학에서 사용하는 선형회귀 식
머신러닝/딥러닝에서 사용하는 선형회귀 식
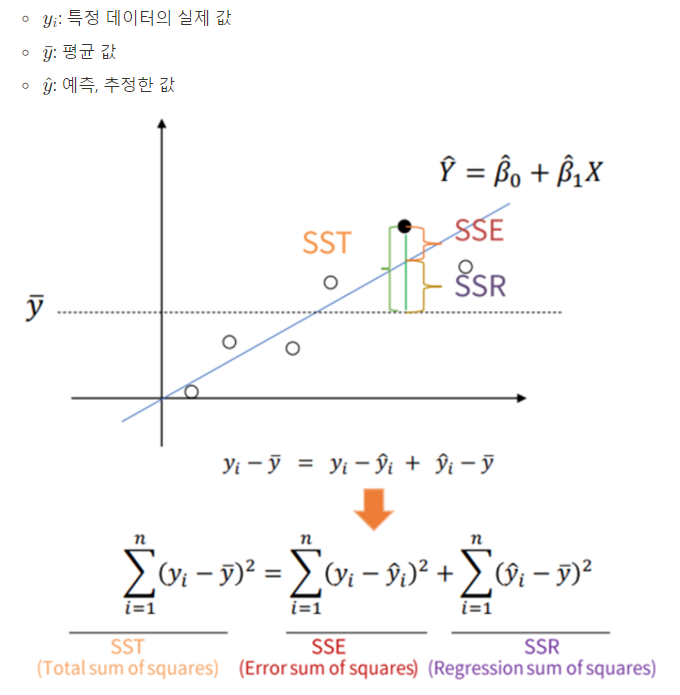
회귀분석 평가 지표
에러 정의 방법 1. 에러 = 실제 데이터 - 예측 데이터 2. 에러를 제곱하여 모두 양수로 만들기, 다 합치기 3. 데이터만큼 나누기 (MSE)
선형회귀만의 평가 지표
R Square : 전체 모형에서 회귀선으로 설명할 수 있는 정도
SQL 코드카타
중성화 여부 파악 보호소의 동물이 중성화되었는지 아닌지 파악 sex_upon_intake 컬럼에 neutered 또는 spayed 아이디 순으로 조회 중성화가 되어있다면 O 아니라면 X
~면 : case when
neutered 또는 spayed : like '%netuered%' or '%spayed%'
아이디 순으로 조회 : order by animal_id
SELECT ANIMAL_ID, NAME,
CASE WHEN SEX_UPON_INTAKE LIKE '%Neutered%' OR SEX_UPON_INTAKE LIKE '%Spayed%'
THEN 'O'
ELSE 'X'
END AS 중성화
FROM ANIMAL_INS
ORDER BY ANIMAL_ID;
Number of Unique Subjects Taught by Each Teacher 각 교사가 가르치고 있는 고유한 과목의 수를 계산하시오
각 교사 : distinct teacher_id
고유한 과목의 수 : distinct subject_id
수 계산 -> count
select distinct teacher_id, count(distinct subject_id) cnt
from teacher
group by 1;
The PADS 이름(직업 첫 글자) There are a total of [직업 수] [ 직업 ]s. 형태로 추출
이름(직업 첫 글자) : concat
직업 첫 글자 : left(직업, 1)
There are a total of : concat 사용
직업 수 : count(직업)
소문자로 직업 : lower
select CONCAT(Name,'(',LEFT(Occupation,1),')')
from OCCUPATIONS
order by Name asc;
SELECT CONCAT('There are a total of ', COUNT(Occupation), ' ', LOWER(Occupation), 's.')
FROM OCCUPATIONS
GROUP BY Occupation
ORDER BY COUNT(Occupation) ASC;
파이썬 코드카타
두 개 뽑아서 더하 정수 배열 numbers에서 서로 다른 인덱스에 있는 두 개의 수를 뽑아 더해서 만들 수 있도록 모든 수를 배열에 오름차순으로 담아 return
서로 다른 인덱스에 있는 두 개의 수 : for i / for j
더해서 만들기 : append
배열 : sorted
def solution(numbers):
answer = []
#서로 다른 인덱스에 있는 두 개의 수
for i in range(len(numbers)):
for j in range(i+1,len(numbers)):
#더해서 .append
answer.append(numbers[i]+numbers[j])
#배열 sorted
return sorted(list(set(answer)))
가장 가까운 같은 글자 문자열 s가 주어졌을 때, s의 각 위치마다 자신보다 앞에 나왔으면서, 자신과 가장 가까운 곳에 있는 같으 글자가 어디 있는지 알고 싶을 때, 수행하는 함수 solution 완성
문자열 위치 : s[i]
문자열 위치에 따른 앞에 있는 글자 : s[0:i]
뒤에서부터 문자의 위치를 찾기 : rindex()
def solution(s):
answer = []
for i in range(len(s)):
if s[i] in s[0:i]:
answer.append(i - s[0:i].rindex(s[i]))
else:
answer.append(-1)
return answer